Дорогие друзья, поздравляем Вас с наступившим Новым Годом! В самый разгар праздников мы подготовили для Вас перевод интересной и актуальной статьи, оригинал которой доступен по ссылке.
С наилучшими пожеланиями команда ПлейсДев!
Отчеты компании Datadog с 2015 года и по настоящий момент наглядно демонстрируют, как клиенты внедряют контейнеры и как эти технологии развиваются, расширяя свое применение для поддержки приложений и бизнес-процессов. Отчет этого года основан на предыдущем издании этой статьи, которое было опубликовано в ноябре 2022 года. О том, что собой представляет инструмент Datadog и зачем его использовать мы уже описали в статье Datadog: краткий обзор платформы для мониторинга.
В отчете за этот год мы можем ознакомиться с тем, как организации используют контейнеры не только для удовлетворения своих повседневных потребностей в инфраструктуре. Скорее, клиенты осваивают следующий технологический рубеж, создавая приложения следующего поколения, повышая производительность разработчиков и оптимизируя затраты.
На основе телеметрических данных, полученных от более чем 2,4 миллиарда контейнеров у десятков тысяч клиентов Datadog, последний отчет выявляет, что организации используют вычисления на базе графических процессоров (GPU) для поддержки стремительного развития своих ИИ-приложений, применяют бессерверные контейнеры для снижения управленческих накладных расходов на разработчиков и используют инстансы на базе архитектуры Arm для сокращения затрат при сохранении уровня опыта конечного пользователя.
Давайте познакомимся поближе с ключевыми достижениями в сфере контейнеров.
Факт 1 — Продолжается рост популярности бессерверных контейнеров
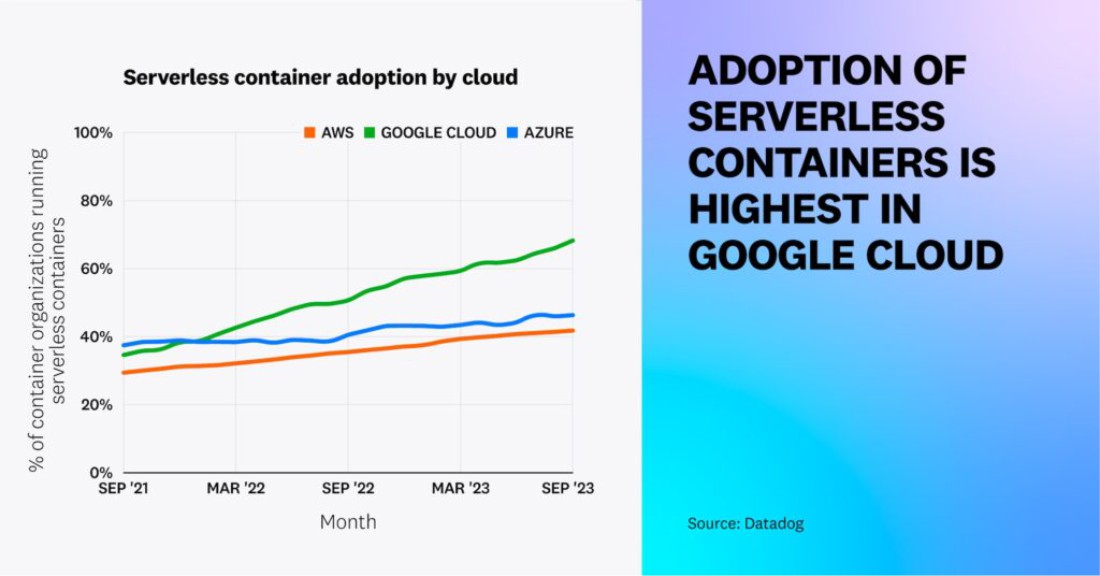
Внедрение бессерверных контейнеров продолжает расти — 46% организаций, использующих контейнеры, в настоящее время используют бессерверные, по сравнению с 31% два года назад. Мы предполагаем, что по мере того, как организации развивают использование контейнеров, многие переходят к бессерверным контейнерам, рассматривая их как шаг навстречу к снижению операционной нагрузки, увеличению гибкости разработки и снижению затрат. Облачные провайдеры полностью предоставляют и управляют инфраструктурой, используемой бессерверными контейнерами, что позволяет командам быстро запускать новые рабочие нагрузки, решая при этом текущие задачи по оптимизации использования ресурсов.
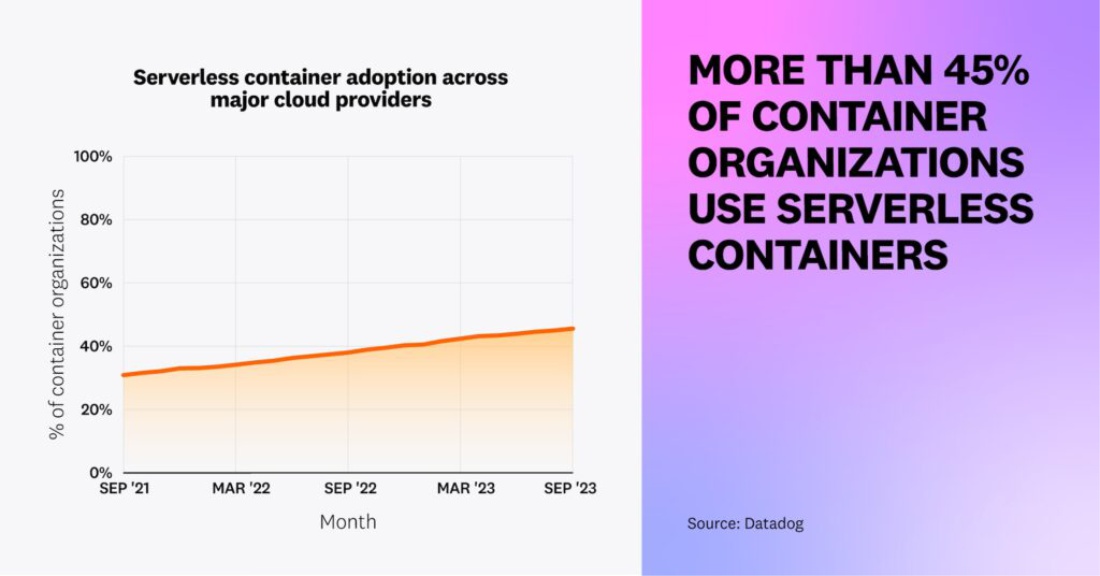
Внедрение бессерверных контейнеров растет во всех основных облачных системах, но лидирует Google Cloud, в котором 68% организаций, использующих контейнеры, запускают бессерверные контейнеры, по сравнению с 35% двумя годами ранее. Этот рост, вероятно, связан с релизом второго поколения Cloud Functions в августе 2022 года, построенного на основе Cloud Run. Больше информации о росте функций, упакованных в виде контейнеров, можно найти в отчете по бессерверным технологиям за этот год.
Считается, что организация использует бессерверные контейнеры, если она пользуется хотя бы одним из следующих сервисов: Amazon ECS Fargate, Amazon EKS Fargate, AWS App Runner, Google Kubernetes Engine Autopilot, Google Cloud Run, Azure Container Instances и Azure Container Apps.
«Сервисы бессерверных контейнеров, такие как GKE Autopilot и Cloud Run от Google, позволяют командам сосредотачиваться на создании приложений, соответствующих основным бизнес-потребностям, при этом экономя на затратах и ресурсах. GKE — самый масштабируемый сервис Kubernetes, доступный в отрасли на данный момент, и он позволяет клиентам использовать облако и контейнеры для запуска критически важных бизнес-приложений, управляемых ИИ. GKE предоставляет ключевые наработки Google, полученные за почти 20 лет масштабного использования контейнеров, для поддержки продуктов, таких как Search, Maps и YouTube. Google открыл исходный код Kubernetes в 2014 году и возглавляет сообщество, внесшее более 1 миллиона взносов в проект. Использование управляемой контейнерной платформы Google Cloud приводит к более эффективному использованию облачных ресурсов и снижению операционной нагрузки для клиентов».
Чен Голдберг, генеральный менеджер и вице-президент, Облачные среды выполнения, Google Cloud
Факт 2 — Увеличилось использование вычислений на базе GPU в контейнеризированных рабочих нагрузках
GPU традиционно применялись для выполнения вычислительно интенсивных задач, таких как компьютерная графика и анимация. Однако это оборудование для обработки данных теперь также используется для эффективного обучения ML и больших языковых моделей (LLM), выполнения выводов и обработки больших наборов данных. Исследуя рост этих рабочих нагрузок, мы наблюдали 58-процентное увеличение вычислительного времени, используемого контейнеризированными экземплярами на базе GPU (по сравнению с 25-процентным увеличением времени вычислений на базе неконтейнеризированных GPU за тот же период времени).
Мы считаем, что рост вычислений на базе графических процессоров (GPU) в контейнерах превосходит его неконтейнеризованный аналог из-за масштаба обработки данных, необходимого для рабочих нагрузок искусственного интеллекта (AI) и машинного обучения (ML). Большие языковые модели (LLM) и другие модели машинного обучения необходимо обучать на сотнях терабайт неструктурированных данных, что является экспоненциально более ресурсоемким процессом, чем типичные требования к обработке данных традиционных веб-сервисов. По мере того как становится доступным все больше вычислительных возможностей на базе графических процессоров, клиенты также могут использовать контейнеры для миграции рабочих нагрузок с одного облачного провайдера на другой, чтобы добиться большей экономической выгоды.
Для запуска рабочих процессов по AI/ML, команды могут использовать предварительно созданные образы, такие как AWS Deep Learning Containers, или применить управляемый Kubernetes сервис, который позволяет им выделять графические процессоры для своих контейнеризованных рабочих нагрузок. Мы считаем, что по мере увеличения инвестиций в приложения на базе искусственного интеллекта следующего поколения и увеличения объема неструктурированных данных, необходимых для их моделей, организации будут все чаще запускать вычисления на базе графических процессоров в контейнерах, чтобы повысить гибкость разработки и лучше извлекать информацию из своих данных.
«Рост популярности графических процессоров был вызван их применением в играх, рендеринге графики и других сложных задачах обработки данных. Сейчас, с ростом числа разрабатываемых приложений на базе AI /ML, неудивительно, что Datadog сообщает о значительном увеличении использования вычислений на базе GPU заказчиками в рамках контейнеризированных рабочих нагрузок. В OctoML за последние 12 месяцев мы наблюдаем значительный рост потребления GPU-вычислений, вызванный внедрением искусственного интеллекта. Наши клиенты ежедневно выполняют миллионы вызовов с использованием ИИ через нашу платформу OctoAI, и темпы роста стремительно ускоряются».
Тони Цзэн, Chief Product Officer, OctoML
Факт 3 — Внедрение вычислительных инстансов на базе Arm для контейнеризированных рабочих нагрузок увеличилось более, чем в 2 раза
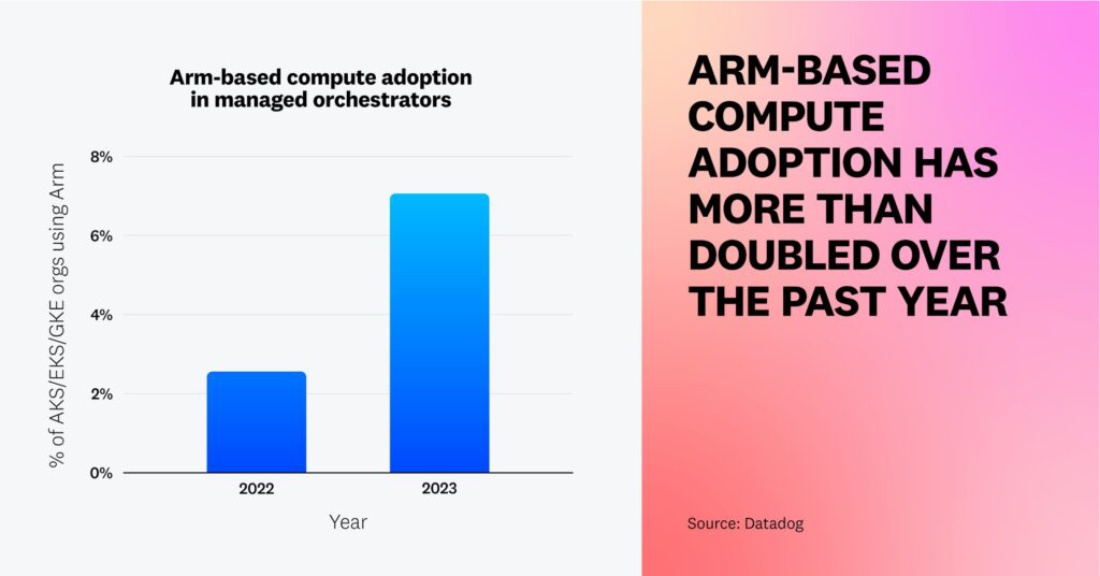
Оптимизированные для контейнеров инстансы на базе Arm могут снизить затраты на 20% по сравнению с инстансами на базе x86 благодаря меньшему энергопотреблению и выделению тепла. Мы видели это на практике в Datadog, где многим инженерным командам удалось успешно снизить расходы на облачные вычисления без ущерба для производительности приложений. Мы предполагаем, что и другие организации добились аналогичных результатов в использовании контейнеризированных рабочих нагрузках — внедрение вычислительных инстансов на базе Arm среди организаций, использующих управляемые сервисы Kubernetes, более чем удвоилось с 2,6% до 7,1% за последний год. Мы ожидаем, что все больше организаций перейдут на Arm, чтобы использовать преимущества с точки зрения затрат, хотя внедрению может препятствовать необходимость рефакторинга приложений для обеспечения совместимости используемых ими языков программирования, библиотек и фреймворков.
“В Datadog наши команды переместили множество рабочих нагрузок, изначально совместимых с процессорами Intel, на вычислительные ресурсы на базе Arm, с целью обеспечить равную производительность и расширенный функционал по более выгодной цене. Для достижения этой цели мы перераспределили наши рабочие нагрузки в зависимости от их размера и требований к производительности, придавая особое внимание созданию эффективной инфраструктуры для централизованной сборки данных. Мы также воспользовались преимуществами крупных обновлений версий и запланированных миграций рассматривая их как возможности для внедрения Arm”.
Йохан Андерсен, Вице-президент по инжинирингу, инфраструктуре и надежности, Datadog
Факт 4 — Более половины организаций, использующих Kubernetes, внедрили горизонтальное автомасштабирование подов (HPA)
Одним из основных преимуществ облачных вычислений является их эластичность — возможность масштабировать инфраструктуру в зависимости от изменяющегося спроса. В рамках Kubernetes одним из способов реализации этой эластичности является HPA, который автоматически разворачивает или уменьшает количество подов в зависимости от текущей нагрузки. Это позволяет организациям поддерживать бесперебойный пользовательский опыт и производительность приложения во время скачков трафика, а также снижать затраты на инфраструктуру в периоды низкой активности за счет автоматической настройки количества запущенных подов.
Ранее мы отмечали, что популярность HPA среди организаций Kubernetes растет, и эта тенденция сохраняется по сей день. Сейчас более половины организаций, работающих c Kubernetes, используют HPA для масштабирования своих рабочих нагрузок.
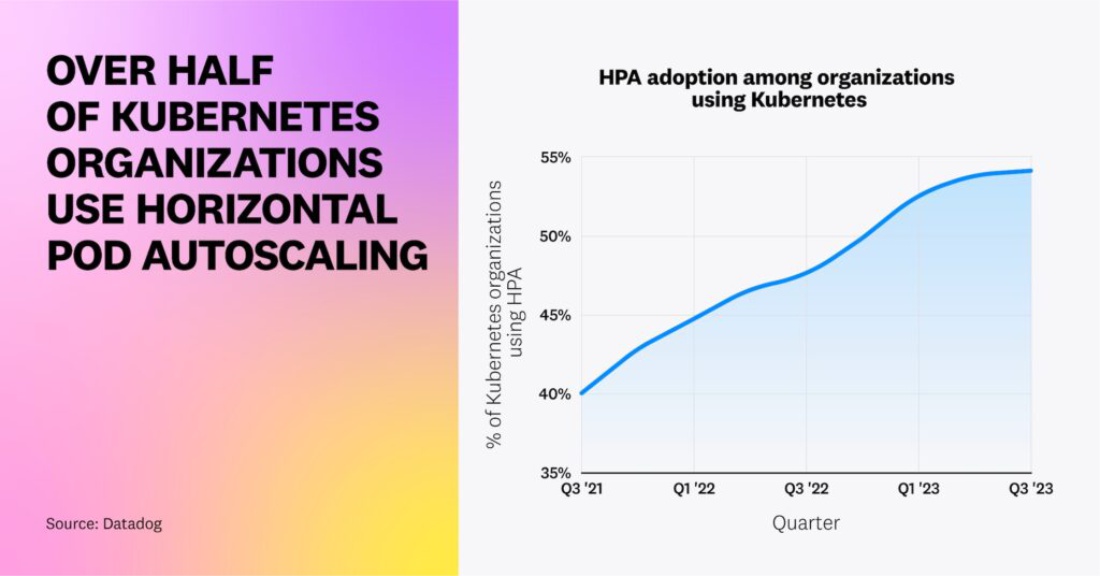
Как только организации внедряют HPA, они не ограничивают его использование небольшим подмножеством своей среды — более 80% из них активируют эту функцию хотя бы на половине своих кластеров, и 45% активируют ее повсеместно.
Мы считаем, что популярность HPA обусловлена тем фактом, что Kubernetes выпустил значительные улучшения этой функции со временем.
Когда HPA был представлен, пользователи могли только автомасштабировать поды на основе базовых метрик, таких как CPU, но с выпуском v1.10 была добавлена поддержка внешних метрик. Поскольку сообщество Kubernetes продолжает расширять возможности HPA, многие организации принимают новые релизы раньше, чтобы настроить свою стратегию автомасштабирования. Например, теперь HPA поддерживает метрику типа ContainerResource (введенную в качестве бета-функции в v1.27), которая позволяет пользователям масштабировать рабочие нагрузки более детально на основе использования ресурсов ключевыми контейнерами, а не целых подов.
Факт 5 — Большинство рабочих нагрузок Kubernetes неэффективно используют ресурсы
Пользователи Kubernetes могут задавать запросы, гарантирующие доступ контейнеров к минимальному объему ресурсов. Однако наши данные свидетельствуют о том, что эти запросы часто являются избыточными; более 65% рабочих нагрузок Kubernetes используют менее половины запрашиваемых ресурсов процессора и памяти — это указывает на сложности оптимизации рабочих нагрузок. Клиенты рассказали нам, что они часто предпочитают выделять избыточные ресурсы для своих контейнеров, несмотря на дополнительные затраты, чтобы избежать проблем с пропускной способностью инфраструктуры на конечных пользователей. Основываясь на наших данных, мы по-прежнему видим много возможностей для организаций оптимизировать использование ресурсов и снизить затраты на инфраструктуру.
Мы считаем, что организации сталкиваются с этими проблемами из-за отсутствия совместимых или доступных инструментов оптимизации затрат. Вертикальное автомасштабирование подов (VPA) — это функция Kubernetes, которая рекомендует запросы к процессору и памяти контейнеров и устанавливает ограничения на основе их прошлого использования ресурсов. Тем не менее, мы обнаружили, что менее 1% организаций Kubernetes используют VPA — и этот показатель остается неизменным с момента нашего последнего анализа внедрения VPA в 2021 году. Мы подозреваем, что низкий уровень внедрения VPA может быть обусловлен тем, что эта функция все еще находится в бета-версии и имеет определенные ограничения. Например, не рекомендуется использование VPA параллельно с HPA на метриках процессора и памяти, и более половины организаций в настоящее время используют HPA. По мере того как организации стремятся к дальнейшему сокращению своих облачных расходов и появляется все больше решений для оптимизации затрат, мы ожидаем более широкого внедрения таких инструментов, как Kubernetes Resource Utilization, которые облегчают выявление рабочих нагрузок, неэффективно использующих ресурсы, и их оптимизацию.
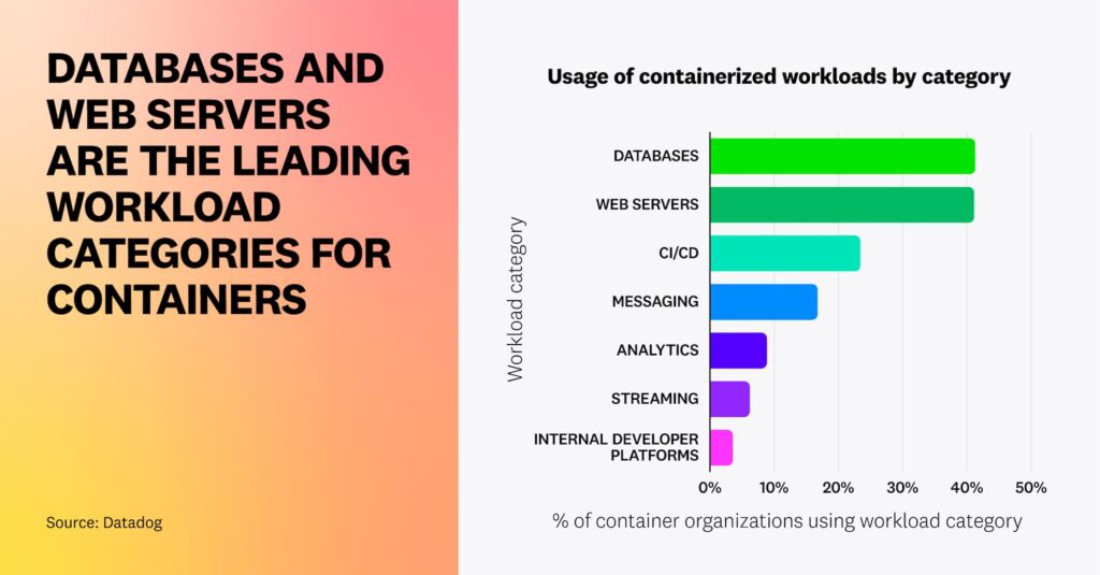
Факт 6 — Базы данных и веб-серверы являются основными категориями рабочих нагрузок для контейнеров
В наших предыдущих исследованиях мы проанализировали наиболее популярные контейнерные образы, а в этом году мы классифицировали эти технологии, чтобы предоставить обобщенные тенденции в использовании контейнеров. Наши данные показывают, что сегодня базы данных и веб-серверы являются наиболее популярными направлениями. Контейнеры давно являются популярным средством для запуска веб-приложений без сохранения состояния и пакетных приложений, но с тех пор клиенты усовершенствовали использование контейнеров для уверенного запуска приложений с сохранением состояния. Более 41% организаций, использующих контейнеры, в настоящее время размещают базы данных в контейнерах. Это подтверждает наши предыдущие данные, согласно которым Redis и Postgres неизменно занимают верхние строчки списка самых популярных образов контейнеров.
С течением времени экосистема контейнеров сформировалась так, чтобы удовлетворять потребности организаций, стремящихся развертывать приложения с отслеживанием состояния в контейнерах. С выпуском StatefulSets в Kubernetes v1.9 организации могли сохранять данные при перезапуске подов, а дополнительные функции, такие как снэпшоты томов и динамическое предоставление томов, позволили им создавать резервные копии данных и избавляться от необходимости предварительного выделения хранилища. Облачные провайдеры, такие как AWS, теперь предоставляют встроенную поддержку для запуска рабочих нагрузок с отслеживанием состояния в контейнерах, включая бессерверные службы, такие как EKS on Fargate, в то время как инструменты с открытым исходным кодом, такие как K8ssandra, также упрощают развертывание баз данных в средах Kubernetes.
“С первых дней поддержки рабочих нагрузок без сохранения состояния Kubernetes перешла к поддержке рабочих нагрузок, ориентированных на данные. Руководствуясь необходимостью получения преимуществ для бизнеса за счет данных в режиме реального времени, а также преимуществами масштабируемости и отказоустойчивости, предоставляемыми Kubernetes, многие компании в настоящее время используют контейнеризированную инфраструктуру для своих рабочих нагрузок с отслеживанием состояния. Базы данных находятся в верхней части списка рабочих нагрузок, выполняемых в Kubernetes, и с учетом возможностей, создаваемых сообществом Kubernetes, и работы, которую выполняет сообщество Data On Kubernetes (DoKC), мы ожидаем, что все больше пользователей будут использовать Kubernetes для размещения рабочих нагрузок с данными”.
Мелисса Логан, Управляющий директор, Data on Kubernetes Community
Факт 7 — Node.js продолжает оставаться ведущим языком для контейнеров
Node.js продолжает оставаться самым популярным языком программирования для контейнеров, за ним следуют Java и Python — тенденция, соответствующая данным 2019 года. Приложения, созданные на Node.js, легки и масштабируемы, что делает их естественным выбором для упаковки и развертывания в виде контейнеров. Четвертый по популярности язык изменился с PHP на Go, что свидетельствует о простоте, масштабируемости и скорости разработки облачных приложений на Go. Процент организаций, использующих C++ в контейнерах, также увеличился, поскольку облачные провайдеры теперь предоставляют более эффективные инструменты сборки, библиотеки и поддержку отладки. (Обратите внимание, что в сумме эти проценты составляют более 100 процентов, поскольку каждая организация может использовать несколько языков.)
Java занимает большую долю рынка корпоративных приложений и продолжает быть самым популярным языком в неконтейнеризированных средах. Исходя из наших разговоров с клиентами, многие из них уже начали (или находятся в процессе) миграции своих приложений, основанных на Java, для запуска в контейнерах. Мы ожидаем дальнейшего роста использования Java в контейнерных средах, обусловленного модернизацией корпоративных приложений и разработкой функций, ориентированных на контейнеры (таких как OpenJDK container awareness).
Факт 8 — Организации с большими контейнерными средами используют service mesh
В 2020 году мы отметили, что организации только начинали использовать технологии service mesh’а, такие как Envoy и NGINX. В этом году мы расширили наше исследование, включив в него обновленный набор технологий, включая Istio, Linkerd и Traefik Mesh, чтобы получить еще более полное представление о том, на каком этапе находится внедрение service mesh сегодня. Мы заметили, что вероятность использования сервис меша возрастает вместе с размером занимаемой организацией площади хостинга — более 40% организаций, в которых работает более 1000 хостов, используют технологию сервис меша.
Одной из причин, по которой сервис мешы более популярны в больших средах, вероятно, является то, что они помогают организациям решать проблемы управления коммуникационными путями, безопасностью и наблюдаемостью сервисов в масштабе. Сервис меш предоставляет встроенные решения, которые снижают сложность реализации таких функций, как mTLS, балансировка нагрузки и межкластерное взаимодействие. Мы считаем, что по мере того, как больше организаций переносят существующие сервисы в контейнеры и расширяют свою инфраструктуру, использование сервис меша будет продолжать расти, особенно при крупномасштабных развертываниях.
Факт 9 — Containerd продолжает заменять Docker в качестве преобладающей среды выполнения контейнеров
В 2021 году мы сообщали, что внедрение containerd среды выполнения находится на подъеме после отмены dockershim в Kubernetes. За последний год мы видели более чем двукратное увеличение использования containerd. В настоящее время 53% организаций, использующих контейнеры, используют containerd, по сравнению с 23% год назад и 8% два года назад. В то время как принятие CRI-O растет менее активно. По мере того как все больше организаций переходят на новые версии Kubernetes, которые больше не поддерживают dockershim, мы наблюдаем снижение использования Docker, которое уменьшилось с 88 процентов до 65 процентов за последний год. (Обратите внимание, что проценты превышают 100 процентов, потому что каждая организация может использовать более одной среды выполнения контейнера.)
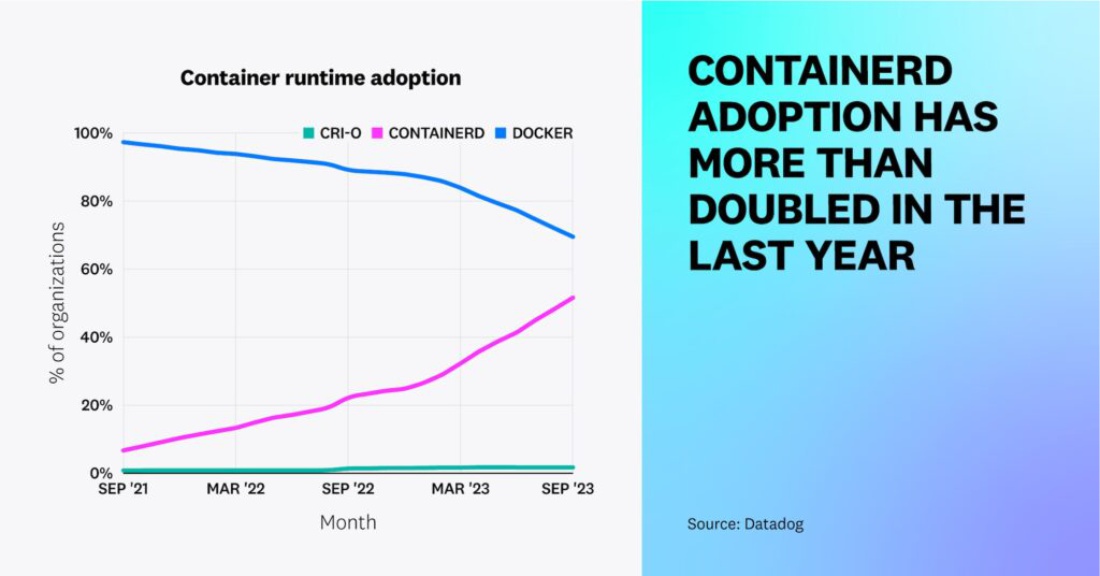
Хотя поддержка Docker устарела с версии Kubernetes v1.24, команды, которые не готовы перейти на новый движок (новую среду выполнения), все равно могут использовать Docker через адаптер cri-dockerd, что, вероятно, объясняет высокий уровень его использования. Однако по мере того, как все больше команд переходят на новые версии Kubernetes и разрабатывают свои среды с учетом будущей поддержки, мы ожидаем, что containerd обгонит Docker в качестве преобладающей среды выполнения.
“Поскольку проект Kubernetes развил встроенную поддержку Docker, удалив dockershim в релизе Kubernetes версии 1.24, увеличение числа развертываний контейнеров с помощью containerd было лишь вопросом времени. Среда выполнения контейнера легковесна по своей природе и активно поддерживается сообществом с открытым исходным кодом. Containerd развился из движка Docker и в настоящее время является одним из лучших проектов CNCF, используемых большинством гиперскейлеров для своих управляемых Kubernetes-предложений”.
Крис Анищик, Технический директор, Cloud Native Computing Foundation
Факт 10 — Пользователи обновляются до более новых версий Kubernetes быстрее, чем раньше
Каждый год Kubernetes выпускает три новые версии для исправления ошибок, устранения проблем безопасности и улучшения пользовательского опыта. В прошлом году мы заметили, что большинство пользователей медленно принимают новые версии, что дает им время протестировать стабильность каждой версии и убедиться, что она совместима с их рабочими нагрузками.
На сегодняшний день Kubernetes v1.24 (на момент написания статьи ей было 16 месяцев) является самой популярный версией, что соответствует историческим тенденциям. Однако в этом году мы наблюдаем значительный рост принятия более новых версий Kubernetes. Сорок процентов организаций, использующих Kubernetes, используют версии (v1.25+), которым примерно год или меньше — значительное улучшение по сравнению с 5 процентами год назад.
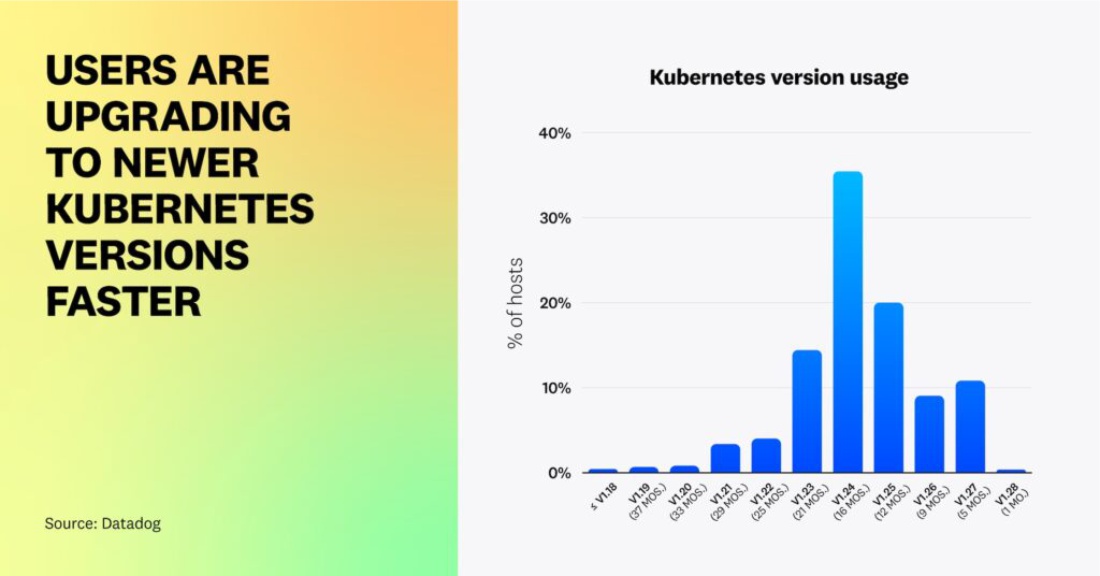
Мы слышали от клиентов, что многие обновляются до более новых версий раньше, чтобы получить доступ к функциям, таким как Service Internal Traffic Policy (выпущен в v1.26) и возможности настройки HPA на основе использования ресурсов отдельных контейнеров (выпущен в бета-версии в v1.27). Эти функции предоставляют пользователям более детальное управление своими кластерами, что может помочь снизить операционные расходы. Управляемые сервисы Kubernetes также играют роль в том, чтобы помочь пользователям быстрее обновлять свои кластеры (например, по умолчанию GKE Autopilot автоматически обновляет кластеры до последней версии Kubernetes через несколько месяцев после ее выпуска). Мы ожидаем, что внедрение релизов Kubernetes будет продолжать расти, по мере того как все больше организаций внедряют управляемые сервисы, такие как Autopilot, и обновляют свои рабочие нагрузки, чтобы воспользоваться преимуществами новых фич Kubernetes. Один из способов сделать это безопасно — обновить рабочие нагрузки, не относящиеся к критически важным задачам, перед более широким развертыванием новых версий в производственных средах.